How Does a Markdown Parser Works
A Look Inside Marked's Source Code
7/16/2017Time to read: 4 min
Marked is a popular markdown parser written in JavaScript. I looked into its source code and found that it was actually not hard to understand. All the important code is in a single JavaScript file which contains merely a thousand lines.
The source code is made up of the following parts:
- Rules/Grammar for block level components (such as headings, blockquotes) as well as a
Lexer. - Rules/Grammar for inline components (such as strong tag, links) as well as an
InlineLexer. - A
Rendererthat outputs final html code - A
Parserthat uses the results from lexer and pass them to Renderer. - Some helper functions.
Alright, I know there are some words that might sounds unfamiliar. I will explain in the section below.
A Brief and Incomplete Introduction of Some Compiler Concepts
I have never taken a compiler design class. So I can't go into details of how a compiler work. Basically, a program needs to go through 5 stages before they can executed.
Lexer
Lexer converts a program into a list of tokens. Tokens are anything that has meaning in a program, for example, variables, operators, semicolons, or even indentations. A simple program like below,
a = 12;
b = 2;
c = a + b;can be converted into the following tokens: a, =, 12, ;, b, =, 2, ;, c, =, a, +, b, ;.
If you want to write a new language, most likely you don't need to implement a Lexer. You can find a lexer implementation in any language of your choice.
var lexer = new Lexer(); // create a lexer object
// Add a rule, so that when lexer finds this pattern in the code,
// it knows to associate this part of code with the tokenType.
// TokenType code be variable, operator, etc.
lexer.addRule(pattern, tokenType);
// Add more rules
lexer.addRule(pattern2, tokenType2);
...
// To use a lexer, usually you can just pass the program in string
lexer.lex("a = 12; b = 2; c = a + b;");How does the lexer work internally? Intuitively, it just read through the code from beginning to end, try each pattern, see if one of them match, if it does, spit out a token and move the read head to the next position.
For markdown, the tokens are the elements, for example
# Beautiful Day
This is a beautiful day, because finally someone reads my blog
> Thank Youare made of three tokens, a level 1 heading (value: "Beautiful Day"), a paragraph (value: "This is a beautiful day, because finally someone reads my blog") and a blockquote (value: "Thank You").
Parser
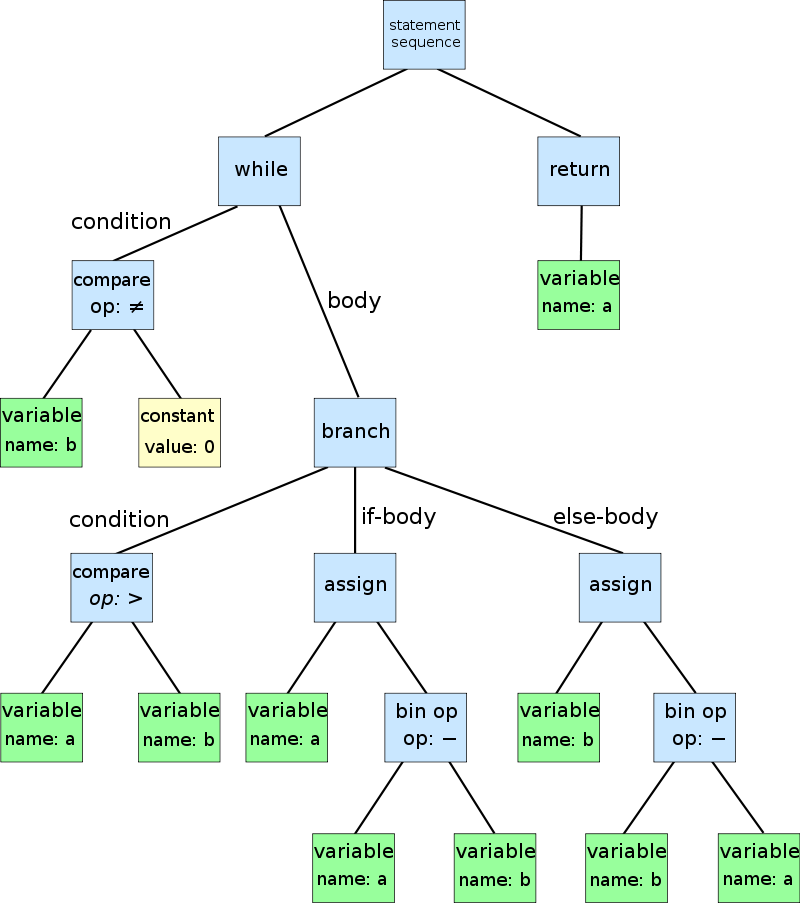
A parser will try to understand the program in a higher level than lexer. Based on the tokens, parser can split the program into different sections. For example, if it sees a semicolon token, it knows that the tokens before and after are two different statements. If it sees a operator surrounded by variables, it's probably an expression. Some section might contain multiple smaller sections. For example, a if block is composed of a condition expression, the then clause, and possibly the else clause. We can view the structure of a program as a tree. The root is the whole program, and the leaves are variables, constants, operators, etc. This tree is called AST (Abstract Syntax Tree). Below is an example of AST from Wikipedia
In terms of markdown, a parser doesn't need to build a AST. This is how the parser in Marked.js is written:
var out = '';
while (this.next()) { // while there is still a next token
out += this.tok(); // convert this token to html string and append to an variable call out
}
return out;Yeah, that's right, since markdown doesn't have many nested structures, it just parse the token one by one in order.
Lexer and parser are all we need in order to parse a simple language as markdown. If you are interested in learning further steps in compiling/interpreting a programing language, I would suggest watching this introductory video.
Lexer VS InlineLexer.
In Marked.js, there are two kind of lexers, their implementations are very similar.
Lexer breaks the input string into tokens like heading, code, table, blockquotes, etc.
After lexer generates those tokens, a parser will try to convert each token into html output. If a token is very simple, such as space, parser will just do the conversion itself (just return an ' ').
If a token is more complicated, such as hr (horizontal rule), parser will call a renderer to produce a html string. If a token might contain some inline elements, such as a paragraph might contain bold tags, parser will call inlineLexer to lex the token further more.
It's interesting that inlineLexer actually reduces the steps from a raw string to html output. When it finds an match with a rule, it will simply return a html output instead of returning a token.
The Process
So to sum up, this is how Marked.js turns a markdown in string form into html output (also in a string):
- Construct Lexer and inlineLexer with regex rules that matches different element of markdown.
- Call Lexer on the input string, turning it into an array of tokens.
- Parser iterate over the tokens, convert the tokens into html strings.
- If a token might contain inline elements, call inlineLexer on it to find the smaller elements, then concat the output html for those smaller elements.
- Concat the outputs for all tokens.
Why Do We Care
Why do we even bother looking into the source code of an library? I think it's interesting to see how things work. As inexperience developers, we tend to view some libraries as pure magic and try to avoid it's internal. But as soon as we dig into them, we will find that they are actually very reasonable.
What interests me about this particular library is that, since it breaks the parsing of markdown into several steps, what if we change the renderer to output React elements instead of html strings? I will do more research on it and hopefully have a post about it. Stay tuned.